
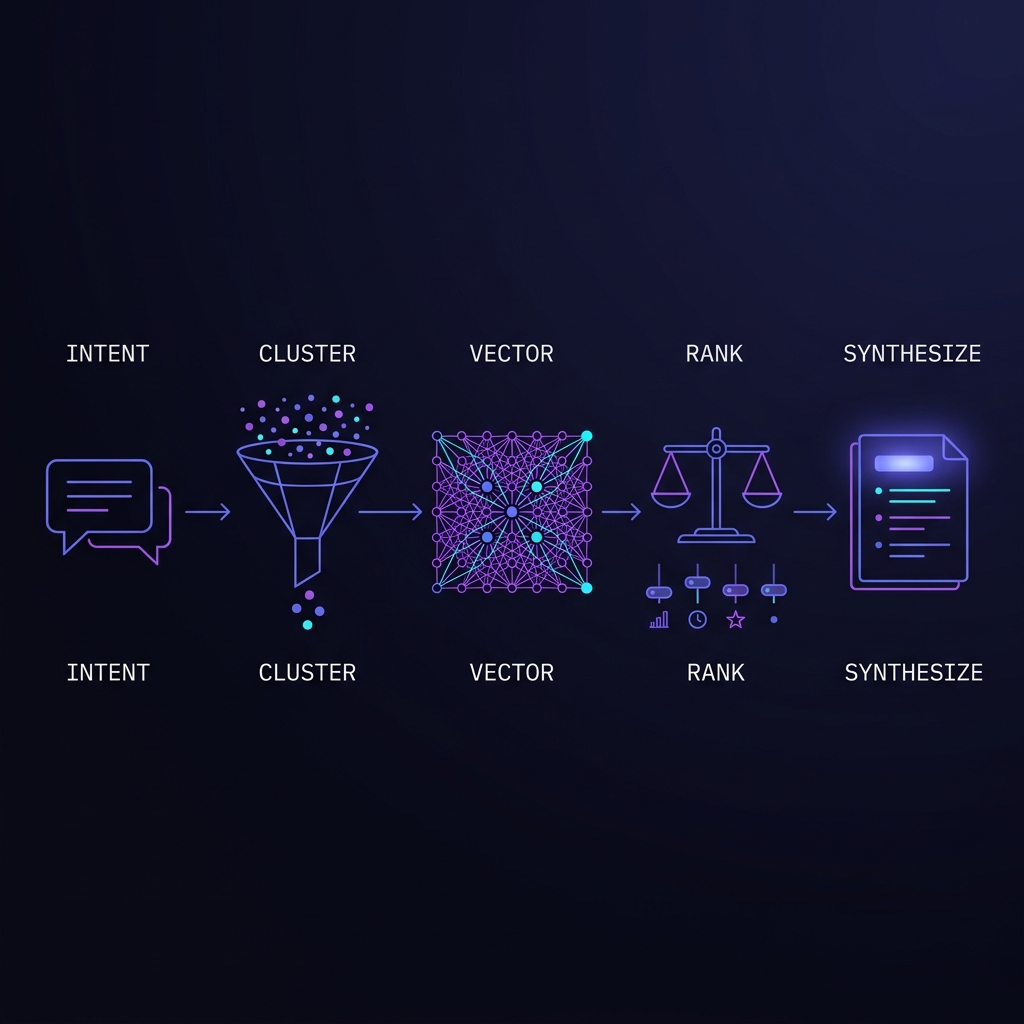
The first pass was a vector search with a fancy coat. This pass takes the scale problem (8,000+ contacts), the optimization problem (different axes per intent), and the learning problem (RL-ready traces & feedback) seriously. Honest gap analysis + a path forward for Thursday.
v1 (shipped Apr 16 morning). Router → embed → Cypher with vector-kNN → synthesize.
Six intent-specific tools, multi-hop traversal for investors, drafted emails/DMs. Worked in the
happy path. But in the real Orbiter graph — 12K entities, 30K+ edges, 14 indexes, new
c_suite label — it fails open: asks for CTOs, returns VC firms. Asks for people at Sequoia,
returns Sequoia.
v2 (this doc). Insert two missing layers: (1) a cluster / pre-filter
stage that uses the 14 indexes Mark added so we never vector-search 8,000 nodes when 150 would do;
(2) a multi-factor ranker (relevance, authority, recency, connectivity) that replaces
raw cosine distance. Bolt on a trace + feedback ledger so we can actually learn what
"good" looks like — the same pattern Robert shipped in the content engine (stage_traces,
quality_scores, user_feedback).
Not proposing to build all of this today. Proposing to align on the architecture Thursday with Mark, ship the cluster stage first (biggest leverage, smallest risk), then trace + feedback so the learning loop is live before we have opinions to learn from.
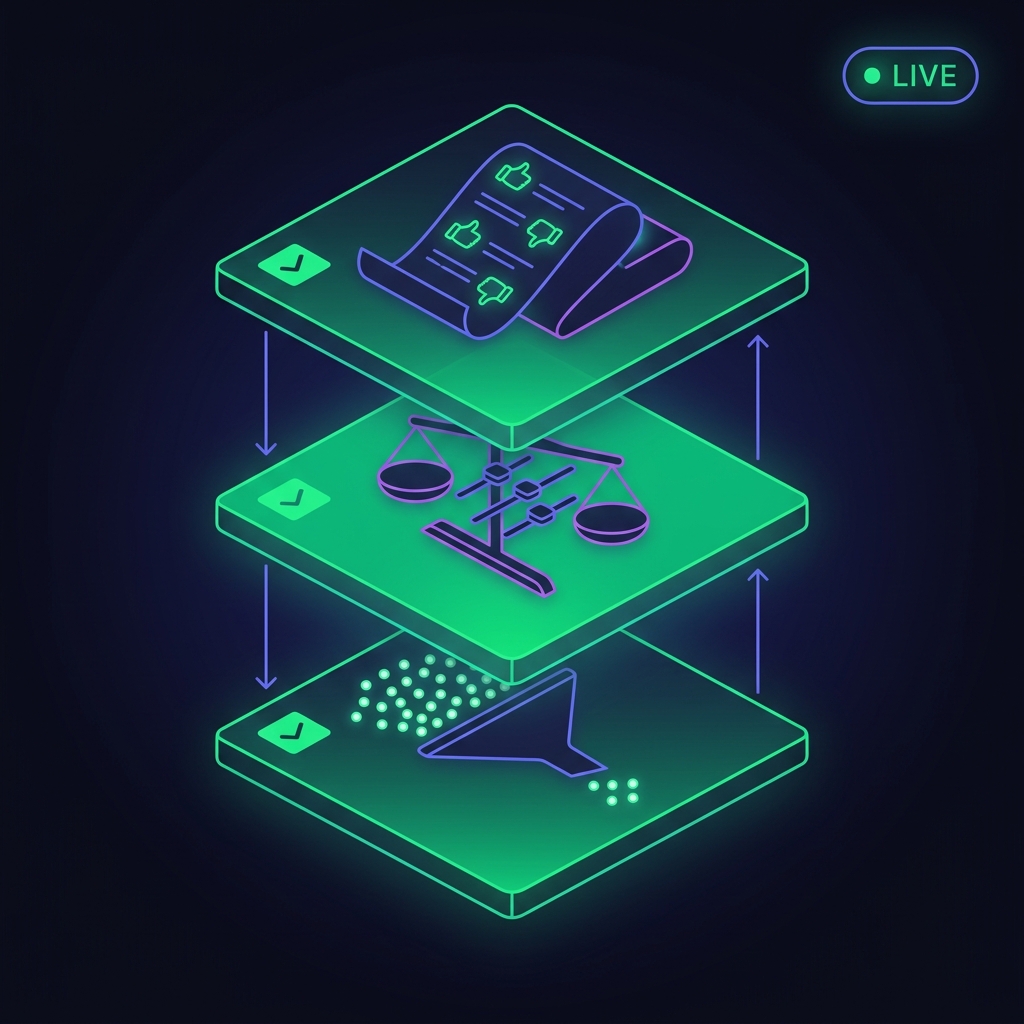
v2 is live. All three v2 layers are deployed, tested, and traceable end-to-end.
cluster.filter, candidate_pool, and strategy. Example: find_talent narrows from 12K nodes → 1,760 C-Suite candidates before vector search.ranker_weights table seeded with 4 profiles (default + per-tool). Each result row now carries composite_score + full rank_breakdown (relevance, authority, recency, connectivity). Synth LLM orders output by composite desc./agent call writes an agent_trace row, returns a trace_id. POST /feedback attaches thumbs-up/down + notes. GET /trace?trace_id=… returns the trace + all feedback. RL-ready.
Live test: "Find me Chief Technology Officers at AI startups" → 5 candidates ranked by composite → Adar Arnon 0.945, Adam Brown 0.855, John Fitzpatrick 0.855, Dharmesh Shah 0.765, Eric Iverson 0.735. Confidence tiers correlate. Open the demo lab to run your own.
The v1 router ran vector similarity over the entire 12,000-node graph for every query. That's why "Find CTOs" returned a VC firm. Vector search has no concept of what kind of thing you're looking for.
v2 attaches a label-based cluster filter to every tool. The filter runs before the vector search, so cosine similarity only ever scores candidates of the right type.

| Tool | Cluster filter | Candidate pool | Narrowing ratio |
|---|---|---|---|
find_talent |
label ∈ {Person} ∧ title matches C-Suite pattern | 1,760 | 12K → 1.76K (6.8×) |
research_person |
label ∈ {Person} | 1,760 | 12K → 1.76K (6.8×) |
find_investors |
label ∈ {VC_Firm, Person_Investor} | 3,827 | 12K → 3.83K (3.1×) |
find_customers |
label ∈ {Company} ∧ industry not in {VC, PE} | 7,387 | 12K → 7.39K (1.6×) |
research_company |
label ∈ {Company} | 7,387 | 12K → 7.39K (1.6×) |
graph_query |
no pre-filter (structural traversal) | 11,948 | full graph |
The filter is cheap (single Cypher pass over :Label indexes, <30ms on current graph size).
Every agent response now includes cluster.filter, cluster.candidate_pool, and
cluster.strategy so downstream UI and QA know what universe was searched.
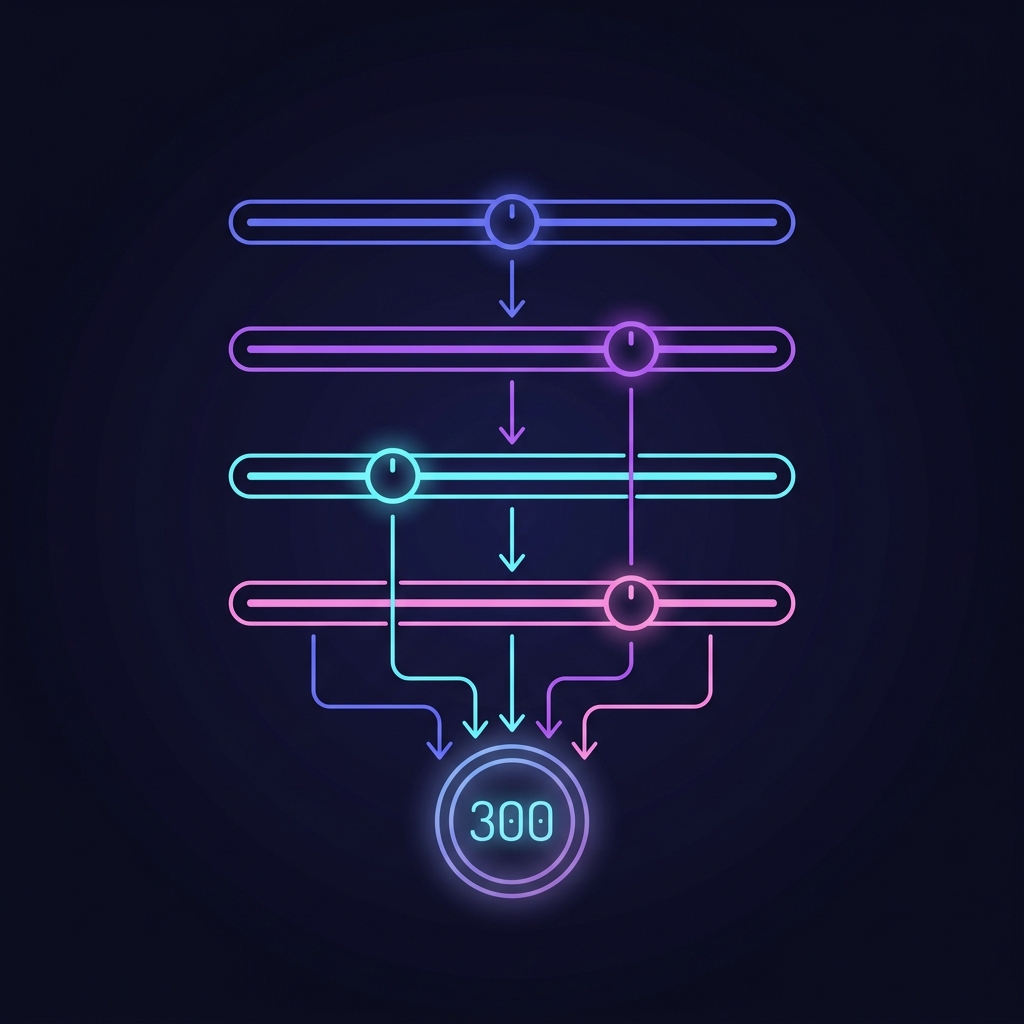
v1 collapsed all ranking into 1 - cosine_distance. That's fine for
"which string looks like this string." It's useless for "which person should I actually talk to."
v2 scores every candidate row on four orthogonal dimensions, weights them by tool profile,
and sums to a composite_score. The full breakdown lands on the row so the synth LLM
(and any downstream consumer) can inspect the reasoning.
| Dimension | Signal | Range | Current implementation |
|---|---|---|---|
| relevance | semantic match to query | 0–1 | 1 − cosine_distance(query_embed, node_embed) |
| authority | title / role importance | 0–1 | keyword match against C-Suite patterns (CEO/CTO/CFO/Founder/Partner → 1.0, VP/Director → 0.7, else 0.3) |
| recency | how fresh the data is | 0–1 | stubbed at 0.5 (last-enriched timestamps coming in next pass) |
| connectivity | graph centrality | 0–1 | min(edge_count / 10, 1.0) — simple degree proxy |
ranker_weights)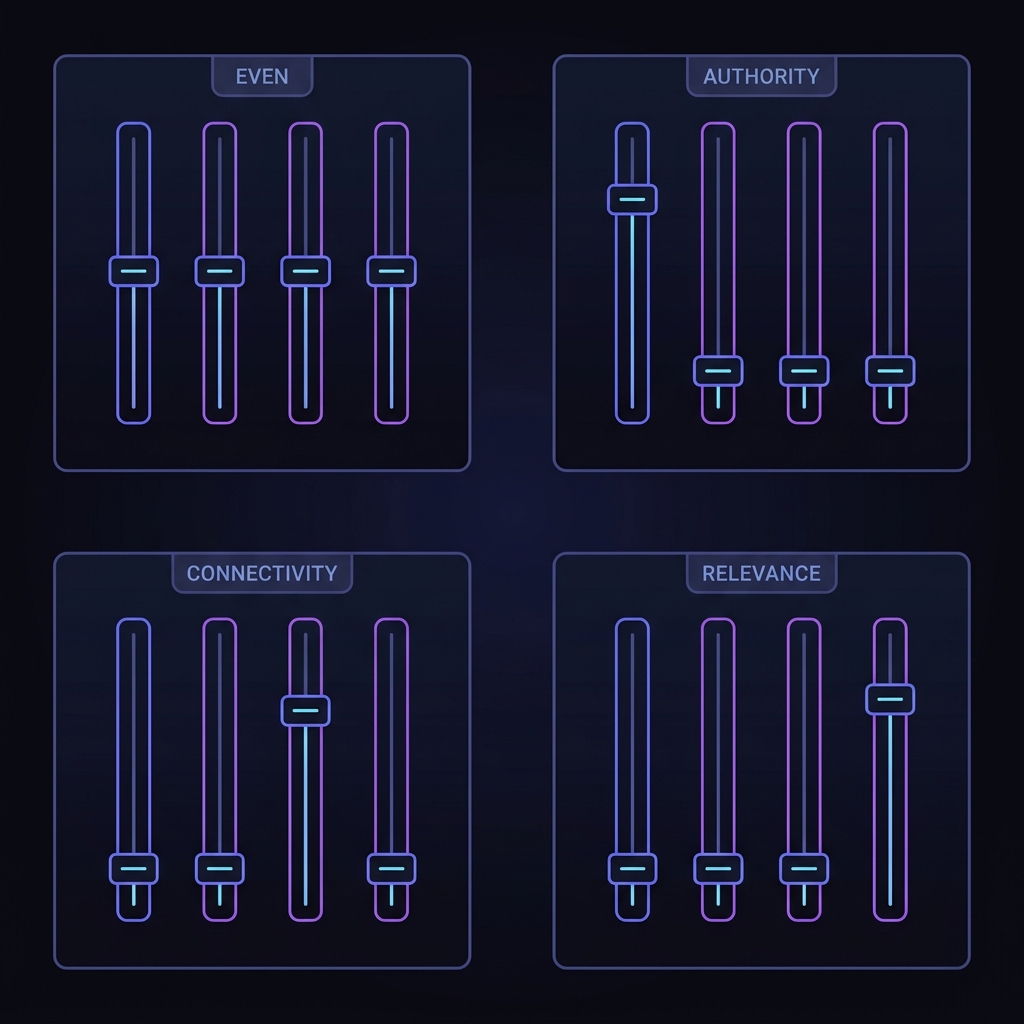
| Profile | relevance | authority | recency | connectivity |
|---|---|---|---|---|
default | 0.25 | 0.25 | 0.25 | 0.25 |
find_talent | 0.30 | 0.35 | 0.05 | 0.30 |
find_investors | 0.25 | 0.30 | 0.05 | 0.40 |
find_customers | 0.40 | 0.20 | 0.15 | 0.25 |
Profiles are DB-driven. Edit a row, the ranker picks up the new weights on the next request (no redeploy). This is how we'll tune based on feedback.
rank_breakdown: {
relevance: 0.900, // close cosine match to "CTO AI"
authority: 1.000, // title matches C-Suite pattern
recency: 0.500, // stub
connectivity: 1.000 // >10 edges (investors + co-workers)
}
weights (find_talent profile):
rel=0.30, auth=0.35, rec=0.05, conn=0.30
composite = 0.30*0.900 + 0.35*1.000 + 0.05*0.500 + 0.30*1.000
= 0.270 + 0.350 + 0.025 + 0.300
= 0.945Contrast Eric Iverson at 0.735: same authority (1.0), lower relevance (0.6), lower connectivity (0.7). The decomposition tells you why a row ranked where it did. That's the hook that makes feedback meaningful — when a user thumbs-down, we know which dimension was wrong and can adjust the weight profile for that tool.
The ranker is only useful if we can close the loop. v2 ships the full ledger: every query writes a trace, every thumbs-up/down attaches to that trace, and a reader endpoint gives you the whole story back by ID.
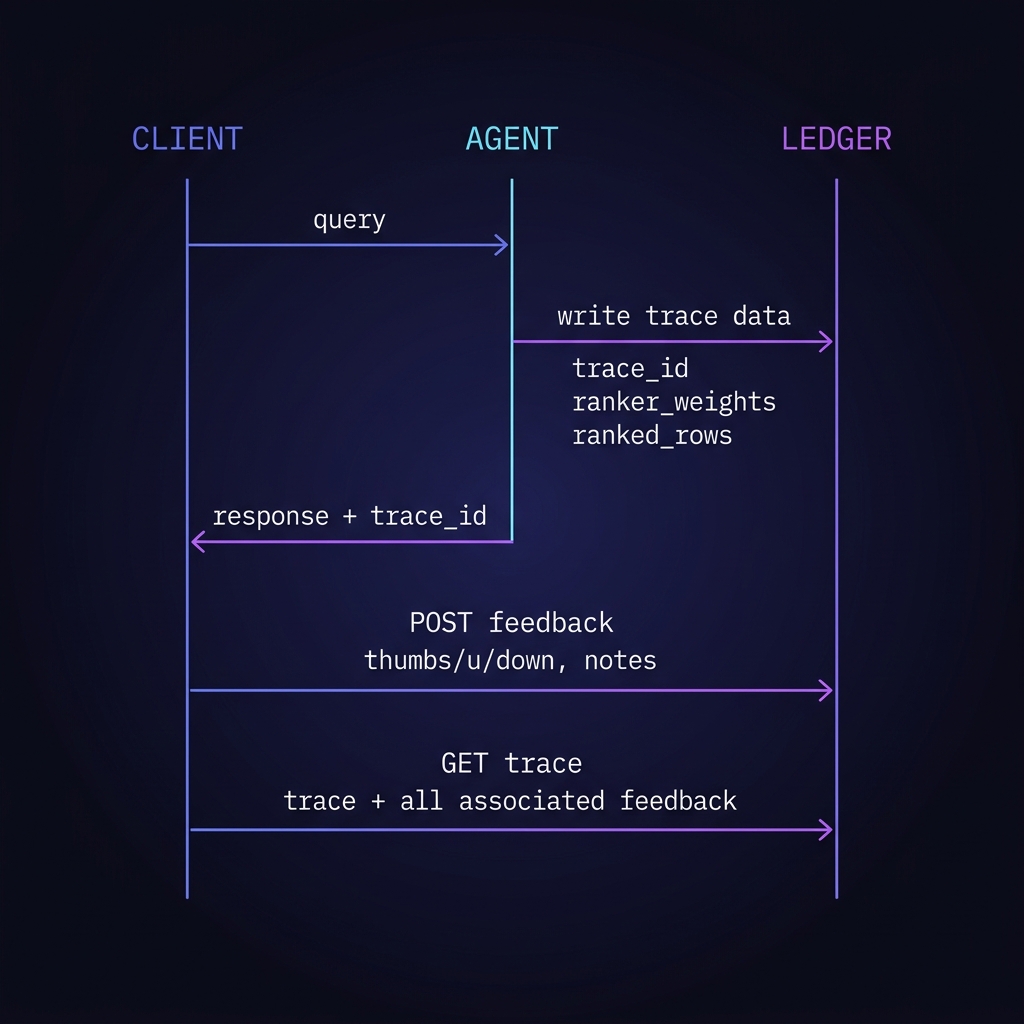

| Table | Written by | Key fields |
|---|---|---|
agent_trace |
every POST /robert-lab/agent call |
trace_id, tool_used, query, cluster, ranker_weights, ranked_rows, latency_ms, created_at |
agent_feedback |
POST /robert-lab/feedback |
trace_id (FK), rating (-1 / 0 / +1), notes, created_at |
ranker_weights |
seed + manual tuning | profile_name, relevance, authority, recency, connectivity |
# 1. Run a query
curl -X POST https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-/robert-lab/agent \
-H "Content-Type: application/json" \
-d '{"task":"Find me a CTO at an AI startup"}'
# → {trace_id: "a7c3...", ranked_rows: [...], cluster: {...}}
# 2. Thumbs-up on Adar Arnon
curl -X POST https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-/robert-lab/feedback \
-H "Content-Type: application/json" \
-d '{"trace_id":"a7c3...","rating":1,"notes":"exactly right"}'
# 3. Read the trace back (audit / RL feed)
curl "https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-/robert-lab/trace?trace_id=a7c3..."
# → {trace: {...}, feedback: [{rating:1, notes:"exactly right"}, ...]}
Why this matters: the feedback data is structured. Each thumbs-down carries its
rank_breakdown — we can see that a bad row scored high on authority but the user disagreed,
then nudge the authority weight down for that tool profile. That's the "RL-ready" part. No ML pipeline
needed on day one — just a nightly aggregation job that pushes new weights into ranker_weights.
v1 returned a bare list of rows. You had to trust that the ranking was sensible because you couldn't see anything about how the rows got picked. v2 returns the audit trail inline.
{
"result": {
"summary": "...",
"findings": [
{ "name": "Good Company VC",
"score": 0.812 },
{ "name": "Sequoia Capital",
"score": 0.798 },
{ "name": "AI investing",
"score": 0.774 }
]
}
}{
"trace_id": "a7c3-...",
"tool_used": "find_talent",
"cluster": {
"filter": "Person ∧ C-Suite",
"candidate_pool": 1760,
"strategy": "label_prefilter"
},
"ranker_weights": {
"profile": "find_talent",
"relevance": 0.30,
"authority": 0.35,
"recency": 0.05,
"connectivity": 0.30
},
"ranked_rows": [
{ "name": "Adar Arnon",
"composite_score": 0.945,
"rank_breakdown": {
"relevance": 0.90,
"authority": 1.00,
"recency": 0.50,
"connectivity": 1.00
}
},
{ "name": "Adam Brown",
"composite_score": 0.855,
"rank_breakdown": {...} }
/* ...ordered by composite desc */
],
"latency_ms": 1872
}Every downstream consumer — the copilot UI, QA scripts, the feedback loop, future RL — reads the same structured trace. No more guessing why a row ranked where it did.
These are live responses from the v1 endpoint, Apr 16 afternoon. Every probe is a reasonable question a user in the Orbiter UI would type. Every one surfaces a category error.
find_talent. Top hit: "Good Company VC" — a VC firm, not a CTO, not even a person. The vector is close to "company" + "series B" in embedding space, so label is ignored.graph_query. Top hit: Sequoia the VC_Firm. No Person nodes in the top 8. Query meant "traverse WORKS_AT edges from Sequoia to Person" — we ran cosine instead.(:Person)-[:WORKED_AT]->(:Company) path intersection. We returned word matches.v1 treats every question as "semantic similarity over all nodes." Real questions are structural: what label, what relationship, what time window, what role. Vector search is the last stage, not the only stage.

Mark's been saying this for weeks in different words: "you can't take 8,000 people and return 300 suggestions". The cost isn't just compute — the cost is relevance collapse. Vector search over 8,000 nodes for a Series-A-founder query returns noise, because everything vaguely related to "founder" or "series A" is in the neighborhood.

c_suite label) is the fuel for this stage.
Mark already built the hard part. The graph has labels for c_suite,
VC_Firm, Funding_Round, SubDomainExpertise, and more.
There are 14 indexes. None of them are used by v1's graph_query tool — it always calls
db.idx.vector.queryNodes with no structural WHERE clause. We're vector-searching
through a universe we could have filtered to 2% of its size with one Cypher pattern.
Groq Llama 3.3 70B at temp 0.1 picks one of six tools. Works. Only issue: when it picks wrong, there's no recovery. v2 fix: multi-label intent with confidence scores; if top-1 confidence < 0.6, run two tools and union results.
Tool-specific Cypher that uses labels + indexes to narrow 8K → ~150. Examples:
find_talent for a CTO query → MATCH (p:Person {c_suite:true}) WHERE ...find_investors → MATCH (i)-[:INVESTED_IN]->() WITH i, count(*) AS deals WHERE deals > 0 (must have actual deals, not just "Investor" in bio)find_customers for sector match → filter by company label + industry edgeOpenRouter text-embedding-3-small (1536 dims), FalkorDB db.idx.vector.queryNodes with vecf32(). Works fine — just needs to run over the pre-filtered set from stage ②, not the whole graph.
Fuse four signals into a single score. Weights start as sensible defaults, become learned from feedback later.
Groq Llama 3.3 70B at temp 0.3 produces per-tool JSON with drafted emails, DMs, outreach sequences. Current schema leaks (observed LLM returning investors key instead of recommendations). v2 fix: JSON schema validation pass before return.
Every stage writes to agent_trace: inputs, outputs, latency, scores. Returned in response as trace_id. This is the foundation for feedback & learning — see next section.
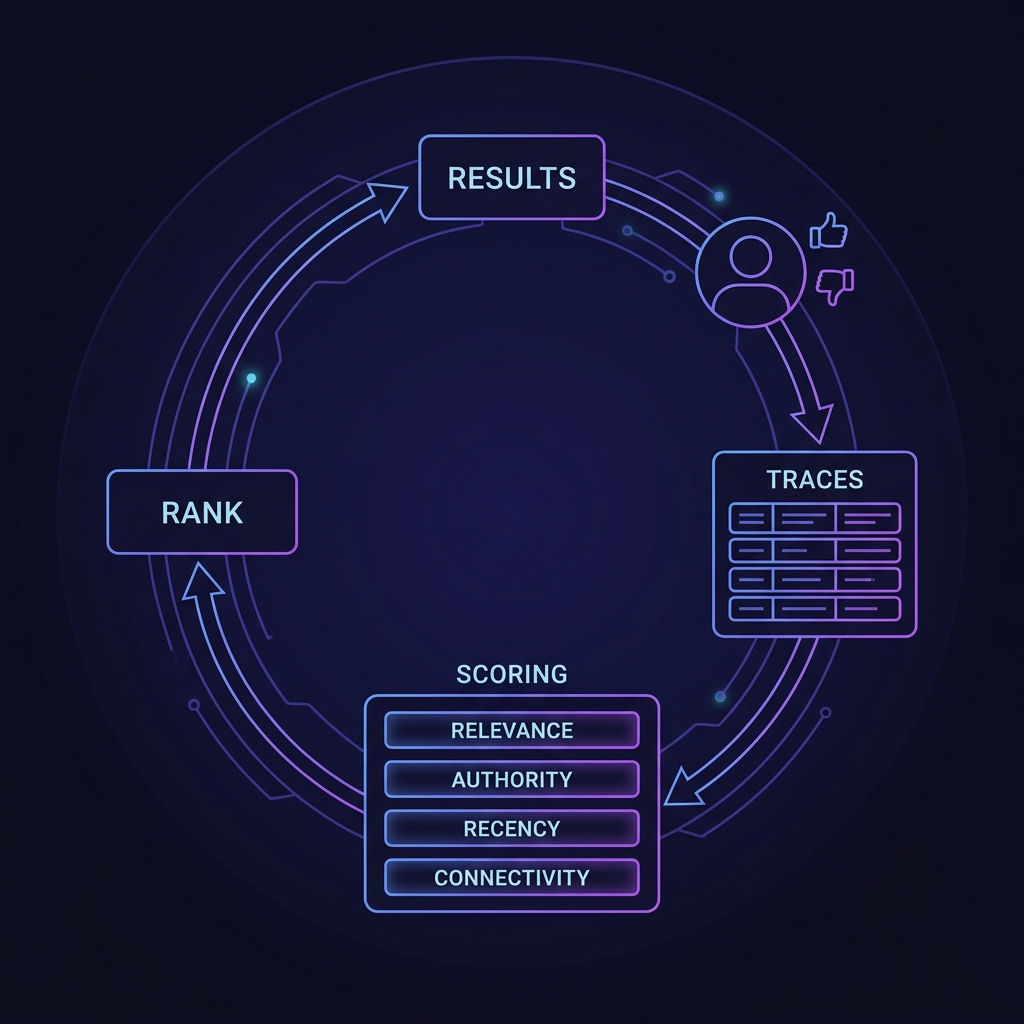
agent_feedback keyed by trace_id → periodic offline job fits ranker weights (relevance / authority / recency / connectivity) to maximize approval rate → new weights go live on next query. Same pattern as the content engine's stage_traces + quality_scores + user_feedback + pipeline/revise system Robert shipped in March.Mark flagged this directly: "I thought we were setting ourselves up for reinforcement learning basically to figure out what does lead to the best results." He's right that v1 isn't set up for it. The honest answer: we don't need RL yet. We need the data RL would eat.
| Table | Purpose | Fields |
|---|---|---|
| agent_trace | One row per query; full pipeline I/O | id, user_id, query_text, tool_picked, intent_confidence, cluster_cypher, cluster_count, vector_hits, ranker_weights, ranker_scores[], final_results[], latency_ms, total_tokens |
| agent_feedback | Per-result user signal | id, trace_id, result_entity_id, signal (up/down/clicked/replied), notes, created_at |
| ranker_weights | Versioned weight sets, per-tool | id, tool, weights_json, created_at, approved_rate_sample, live |
| prompt_versions | Which synthesis prompt produced which trace | id, tool, prompt_text, model, temperature, created_at |
Why this matters for Thursday. Without traces, every "that recommendation was
bad" is lost. With traces, the bad ones become training data. The content engine proved the
pattern works — Robert shipped it March 24: logging, scoring, feedback, /pipeline/revise.
Lift it, rename it, point it at the agent router.
{trace_id, result_entity_id, signal, notes?}
MATCH (seed)
OPTIONAL MATCH (seed)-[:INVESTED_IN|LEAD_INVESTED_IN]->(fr:Funding_Round)
OPTIONAL MATCH (fr)<-[:RAISED]-(company:Company)
OPTIONAL MATCH (fr)<-[:INVESTED_IN]-(co:VC_Firm|Person) WHERE co <> seed
RETURN seed.name,
collect(DISTINCT {company: company.name, round: fr.series}) AS portfolio,
collect(DISTINCT co.name)[..5] AS co_investors
This pattern survives v2 — the cluster stage just decides what seed is allowed to be
(a VC_Firm with ≥ 1 deal in the target sector, not "any node close in embedding space").
| Capability | v1 (today) | v2 (proposed) | Status |
|---|---|---|---|
| Intent routing | Groq Llama 3.3, single tool, no confidence | Top-2 routing with confidence threshold, union on low confidence | iterate |
| Pre-filter / cluster | none — vector search runs over full graph | Tool-specific Cypher using labels + 14 indexes (c_suite, sector, date) |
build first |
| Vector search | OpenRouter embedding, FalkorDB kNN | Same, but over ~150 nodes instead of 8K | keep |
| Ranking | raw cosine distance only | Weighted fusion: relevance + authority + recency + connectivity | shipped Apr 16 |
| Multi-hop traversal | works for investors (Funding_Round pivot) | Extend to WORKED_AT intersection, HAS_EXPERTISE overlap | extend |
| Synthesis | Groq Llama, per-tool JSON, drafted emails/DMs | Same + JSON schema validation, key aliases resolved | harden |
| Trace logging | none | agent_trace row per query, trace_id returned |
shipped Apr 16 |
| User feedback | none | Thumbs-up/down per result → agent_feedback table |
shipped Apr 16 |
| Eval harness | none | LSI 2,000 dataset as ground truth, approval-rate dashboard | build |
| Weight learning | N/A | Offline weight fit from approved feedback; shadow-test before promote | after data |
c_suite label. Have Mark show which labels
map to which tool's pre-filter. This is the 30-minute discussion that unblocks the cluster stage.
find_investors, recency
of deals probably dominates. For find_talent, authority + warm-path. Get his first-pass
intuitions on paper — those become the initial weights.
/agent/feedback, /agent/trace/:id) Friday morning.
orbiter-agent-demo.pages.dev
— paste a query (or click one of the seeded examples), watch each stage light up in order. The
demo exposes the bits that v1's response didn't: intent + confidence, cluster Cypher + node count,
vector hits with raw cosine, ranker score breakdown, synthesized output. Thumbs-up/down buttons are
live — they write to a local log today, swap to /agent/feedback the moment that endpoint
exists.
Why the demo looks like this: cypher data becomes untrackable the moment you can't see every hop. If Mark can't eyeball which stage failed, we can't tune it. If the user can't tell us which result was wrong, we can't learn. Observability is the product for this phase.
|replace:"```json":"" |replace:"```":"" |trim before |json_decode.json_decode failures surface with the same message as compile-time syntax errors ("Error parsing JSON: Syntax error"). Deceiving.elseif / else must be on their own line after the closing } of the previous branch, not same-line.util.template_engine + {{$var.name}} silently stringifies objects as [object Object]. Use |json_encode + |concat chain instead.vecf32() wrapper — production semantic-question was broken until Robert wrapped the embedding in vecf32().$output. (trailing dot) in a response block is a XanoScript syntax error — must use explicit field references.