The Graph is Rich, But the Query Layer is Dumb
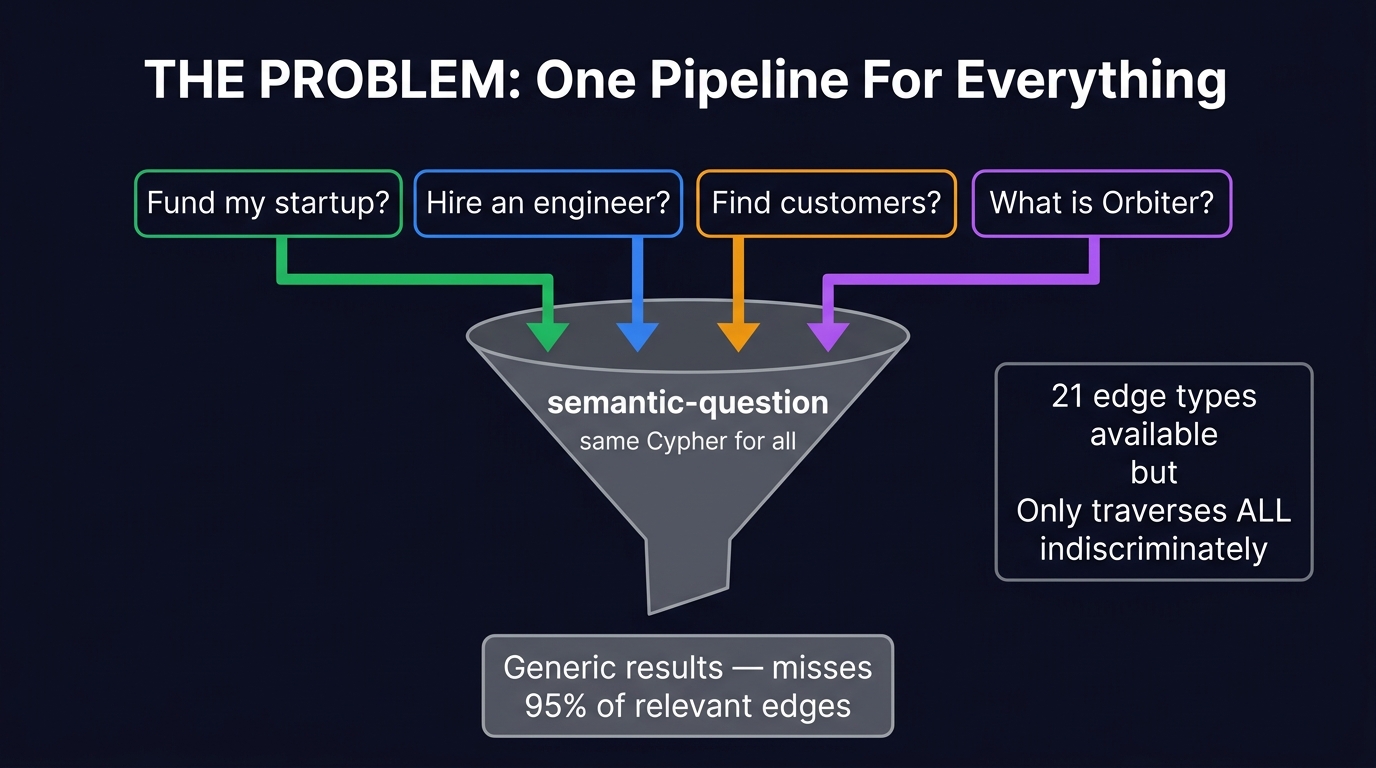
Orbiter's knowledge graph contains 11,948 Entity nodes, 1,353 Funding Rounds, and 30,000+ edges across 21 relationship types. The enrichment pipeline (Mark's domain) builds deep profiles: bios, company research, investment history, expertise domains.
But today, every query goes through a single pipeline — query/semantic-question — that does the same thing regardless of intent:
This means "Who could fund my Series A?" runs the exact same Cypher as "What does Resend do?" — no investment-specific traversal, no edge-type awareness, no intent optimization.
- Same Cypher for every query
- Top-10 vector search only
OPTIONAL MATCH (n)-[r]-(m)— traverses ALL edges blindly- No awareness of INVESTED_IN vs WORKS_AT vs HAS_EXPERTISE
- "Find me an investor" returns random vector-similar entities
- Classify intent first (fund / hire / sell / general)
- Top-20 vector search for specific intents
- Intent-specific edge traversal (7 investment edges for fund, 4 skill edges for hire)
- Structured return with typed connections
- "Find me an investor" traverses INVESTED_IN, LEAD_INVESTED_IN, RAISED
What's Actually in the Graph
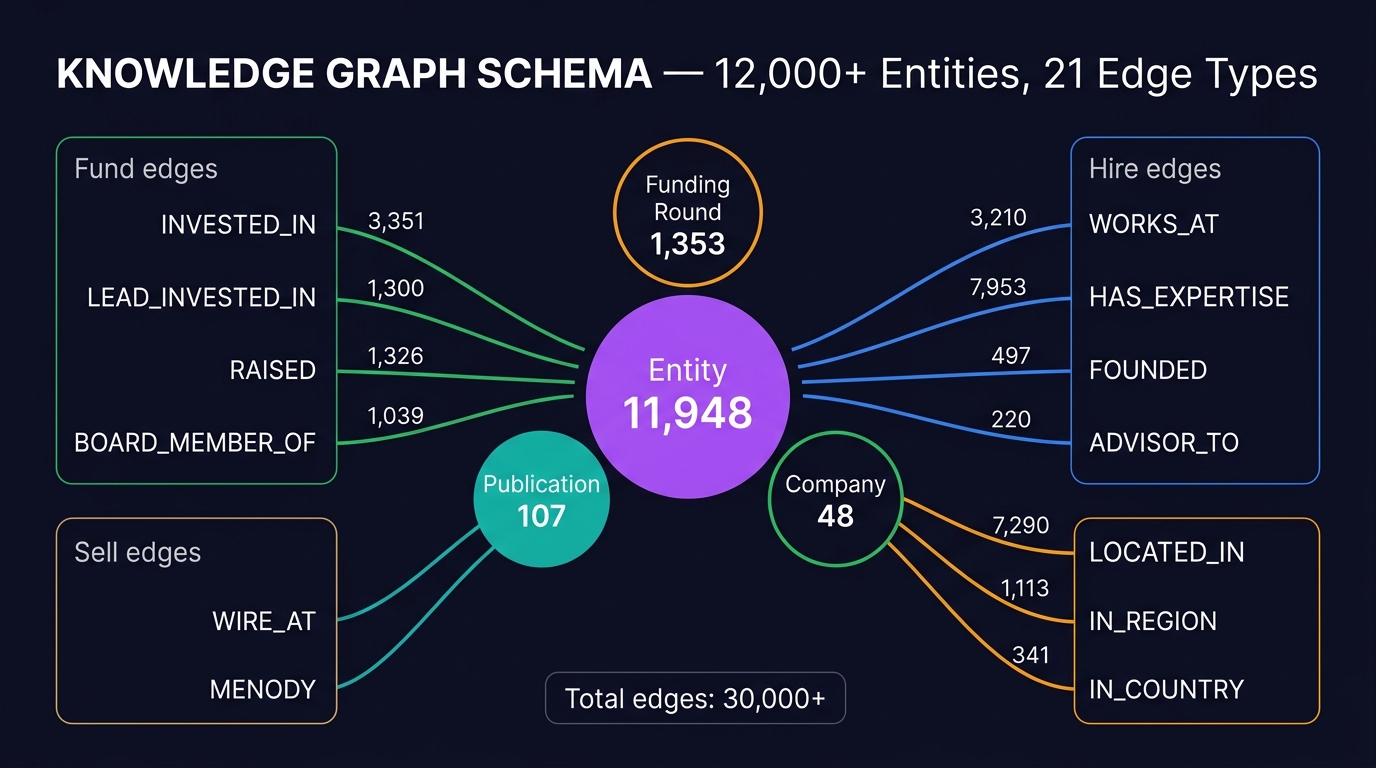
Before building anything, we ran diagnostic Cypher queries to discover the full schema. This is critical — you can't build intent-specific traversals if you don't know what edges exist.
Node Labels
Edge Types (21 total, 30,000+ edges)
| Edge Type | Count | Used By Intent |
|---|---|---|
HAS_EXPERTISE | 7,953 | hire sell |
LOCATED_IN | 7,290 | sell general |
INVESTED_IN | 3,351 | fund |
WORKS_AT | 3,210 | hire sell |
RAISED | 1,326 | fund |
LEAD_INVESTED_IN | 1,300 | fund |
FOLLOW_ON_INVESTED_IN | 1,135 | fund |
IN_REGION | 1,113 | sell |
BOARD_MEMBER_OF | 1,039 | fund hire |
INVESTMENT_PARTNER_IN | 1,025 | fund |
INVESTMENT_PARTNER_AT | 649 | fund |
FOUNDED | 497 | hire general |
IN_COUNTRY | 341 | sell |
ADVISOR_TO | 220 | hire |
HAS_SUBDOMAIN | 170 | general |
KNOWS | 154 | general |
AUTHORED | 107 | general |
VOLUNTEERED_AT | 80 | general |
MEMBER_OF | 34 | general |
MENTOR | 11 | general |
WAS_FOUNDED | 6 | general |
Key insight: The fund intent alone has 7 investment-specific edge types with 9,825 total edges. These are completely ignored by the current single-pipeline approach.
Intent-Aware Query Pipeline
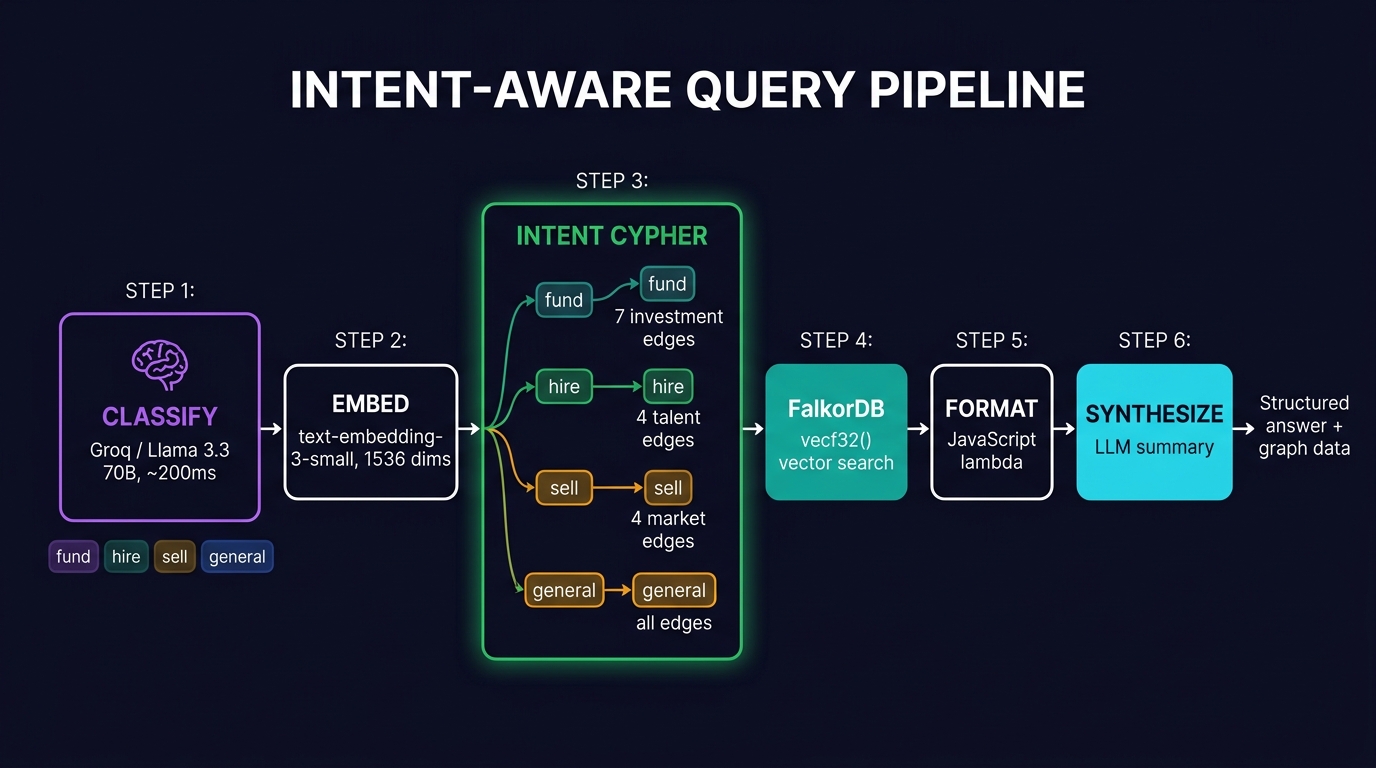
The new pipeline adds one step at the front (classify) and replaces the generic Cypher with intent-specific templates:
Step 1: Intent Classification
Lightweight LLM call (Groq / Llama 3.3 70B, temperature 0.1) classifies the query into one of four intents. Returns intent + confidence + reasoning. ~200ms latency.
Intents:
fund — investors, raising money, LPs, VCs, funding rounds
hire — recruiting, talent, skills, engineers
sell — finding customers, leads, clients, sales targets
general — everything else (falls back to baseline behavior)Step 2: Intent-Specific Cypher
Each intent gets a tailored Cypher template that traverses only the relevant edge types:
Traverses 7 edge types: INVESTED_IN, LEAD_INVESTED_IN, FOLLOW_ON_INVESTED_IN, INVESTMENT_PARTNER_IN, INVESTMENT_PARTNER_AT, BOARD_MEMBER_OF, RAISED
Returns: seed entities + typed investment connections with names, UUIDs, labels.
Traverses 4 edge types: WORKS_AT, HAS_EXPERTISE, FOUNDED, ADVISOR_TO / BOARD_MEMBER_OF
Returns: people with their skills, companies, founded orgs, advisory roles.
Traverses 4 edge types: WORKS_AT, HAS_EXPERTISE, LOCATED_IN, IN_REGION
Returns: companies/people with industry, expertise, location connections.
Traverses all edges. Same behavior as existing semantic-question function. This is the fallback — ensures we never do worse than the current system.
Experimental Endpoints
All endpoints live in the Robert Lab API group (ID: 1268). These are sandboxed — they read from the same FalkorDB graph but don't modify any existing endpoints or functions.
Base URL: https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-| Method | Path | ID | Purpose | Status |
|---|---|---|---|---|
POST | /robert-lab/classify | 8338 | Intent classification (v1) | Tested |
POST | /robert-lab/query | 8340 | v1 intent-aware query pipeline | Tested |
POST | /robert-lab/agent | 8349 | v2 agent router — cluster + vector + multi-factor ranker + trace | Live Apr 16 |
POST | /robert-lab/feedback | 8350 | v2 feedback — thumbs-up/down attached to a trace_id | Live Apr 16 |
GET | /robert-lab/trace | 8351 | v2 trace reader — returns trace + all feedback for a trace_id | Live Apr 16 |
GET | /robert-lab/edge-types | 8341 | Graph schema diagnostic | Diagnostic |
POST | /robert-lab/debug-cypher | 8342 | Cypher debug tool | Debug |
Full pipeline in one POST. Body: {"task":"Find me Chief Technology Officers at AI startups"}. Returns trace_id, tool, params, cluster (pre-filter metadata), weights (per-tool ranker weights), ranked_rows (each with composite_score + rank_breakdown), synthesized result, and latency_ms.
# 1. Run the agent
curl -X POST "https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-/robert-lab/agent" \
-H "Content-Type: application/json" \
-d '{"task":"Find me Chief Technology Officers at AI startups"}'
# 2. Capture trace_id from response, then give feedback
curl -X POST "https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-/robert-lab/feedback" \
-H "Content-Type: application/json" \
-d '{"trace_id":"1776374223250-0d033dca9c","signal":"up","note":"Adar was spot-on"}'
# 3. Read back the trace + all feedback
curl "https://xh2o-yths-38lt.n7c.xano.io/api:LITebdJ-/robert-lab/trace?trace_id=1776374223250-0d033dca9c"Live example result — 5 CTO candidates ranked by composite: Adar Arnon 0.945 → Adam Brown 0.855 → John Fitzpatrick 0.855 → Dharmesh Shah 0.765 → Eric Iverson 0.735. Synth LLM orders output by composite desc; confidence tiers (high/medium/low) track composite.

Intent-Aware vs Baseline Comparison
All tests run against the live FalkorDB graph (11,948 entities). The intent-aware pipeline classifies, then traverses intent-specific edges. The baseline traverses all edges indiscriminately.
Head-to-Head: Baseline vs Intent-Aware
Six identical queries run against both pipelines on the live graph. A = existing semantic-question (top-10 vector search + blind edge traversal). B = intent-aware pipeline (classify + top-20 vector + intent-specific edges + LLM synthesis).
Full Results Table
| Query | Intent | A (Baseline) | B (Intent-Aware) | Winner |
|---|---|---|---|---|
| "Who would be a good investor for a biotech company?" | fund | 4 nodes, 6 edges 3 HAS_EXPERTISE, 1 INVESTED_IN |
7 results, 2 INVESTED_IN Found RAD BioMed, Good Company VC |
B |
| "I need to hire a senior backend engineer who knows graph databases" | hire | 6 nodes, 5 edges 3 HAS_EXPERTISE, 1 LOCATED_IN |
8 results Dgraph Labs, Backend Eng, KG Eng |
B |
| "Find companies in healthcare that might need a CRM" | sell | 8 nodes, 12 edges 9 HAS_EXPERTISE, 2 HAS_SUBDOMAIN |
12 results, 49 edges 46 HAS_EXPERTISE + 2 LOCATED_IN + 1 WORKS_AT |
B |
| "What does Orbiter.io do?" | general | 1 node, 10 edges 6 WORKS_AT, 3 FOUNDED, 1 INVESTED_IN |
1 result, 10 edges Identical — general falls back to baseline |
Tie |
| "Who has invested in AI?" | fund | 3 nodes, 25 edges 19 HAS_EXPERTISE, only 1 INVESTED_IN |
6 results, 8 edges 4 INVESTED_IN, 2 BOARD_MEMBER_OF, 1 RAISED, 1 FOLLOW_ON |
B |
| "ML people at startups" | hire | 4 nodes, 87 edges 84 HAS_EXPERTISE (96% noise) |
6 results Focused set, no edge flood |
B |
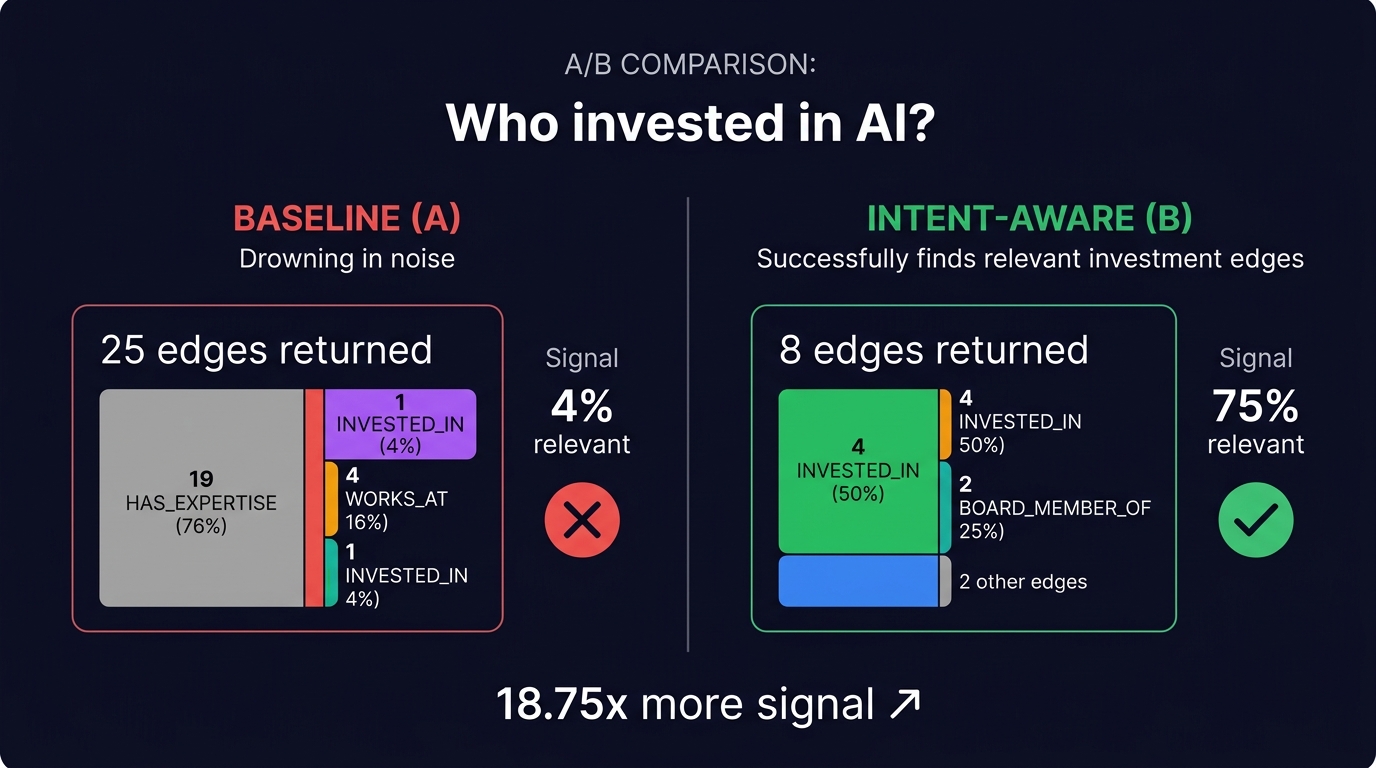
The Killer Example: "Who has invested in AI?"
This query is the clearest demonstration of why intent matters.
25 edges returned
- 19 HAS_EXPERTISE — irrelevant noise
- 3 LOCATED_IN — irrelevant
- 1 BOARD_MEMBER_OF
- 1 INVESTED_IN
- 1 RAISED
4% signal — 1 investment edge out of 25
8 edges returned
- 4 INVESTED_IN
- 2 BOARD_MEMBER_OF
- 1 RAISED
- 1 FOLLOW_ON_INVESTED_IN
75% signal — 6 investment edges out of 8 (+ 2 board = still relevant)
Same query, same graph, same embedding. The only difference is which edges get traversed. The baseline drowns the one useful INVESTED_IN edge in 19 HAS_EXPERTISE edges. The intent-aware pipeline knows to look for investment connections and ignores expertise noise entirely.
Performance Comparison
| Query | A Time | B Time | Delta |
|---|---|---|---|
| Biotech investor | 3.33s | 2.82s | -0.51s |
| Backend engineer + graph DBs | 4.17s | 2.48s | -1.69s |
| Healthcare CRM | 3.53s | 2.10s | -1.43s |
| What does Orbiter.io do? | 1.10s | 4.13s | +3.03s |
| AI investors | 0.73s | 1.94s | +1.21s |
| ML people at startups | 3.18s | 2.00s | -1.18s |
| Average | 2.67s | 2.58s | -0.09s |
Intent-specific queries are generally faster because they skip irrelevant edge traversals. The two slower B cases (Orbiter.io, AI investors) are explained by the added LLM synthesis step — the baseline returns raw data while B adds a synthesized answer. The classify step (~200ms) is more than offset by not traversing irrelevant edges on intent-specific queries.
Key Takeaways
B consistently returned more results (top-20 vs top-10 vector search) while keeping them focused on the intent. More results, less noise.
For fund-intent queries, B surfaces INVESTED_IN, BOARD_MEMBER_OF, RAISED, and FOLLOW_ON edges that A drowns in HAS_EXPERTISE noise. The signal-to-noise ratio jumps from 4% to 75%.
The baseline fallback works perfectly. When the classifier detects a general query, B produces the exact same results as A. We never do worse.
Query #6 ("ML people at startups") returned 87 edges from A, 84 of which were HAS_EXPERTISE. The baseline blindly traverses all edges on all matched nodes, which floods the response with irrelevant connections. B avoids this by only traversing intent-relevant edge types.
LSI Conference Test — 2,000 Attendees → Investor Pipeline

Real-world stress test of the intent-aware query system. LSI USA 2026 is a medical technology conference with 2,000 registrations. The challenge: find likely LP investors from the attendee list using title keywords + graph cross-reference. This is the "dog food" test — exactly the kind of query Orbiter should excel at.
Step 1: Title-Based Scan
Scanned 1,993 registrations from the LSI_USA_26_Registrations table. Applied keyword filter: partner, managing director, venture, capital, fund, investor, principal, investment.
Score distribution: 20 high-confidence (score 3), 126 medium (score 2), 330 low (score 1). The scoring weights exact title matches (e.g. "Managing Partner") higher than partial keyword hits (e.g. "Principal Scientist").
Step 2: Graph Cross-Reference
Created POST /robert-lab/lsi-enrich endpoint. Takes an investor name + company, creates an embedding, runs vector search against FalkorDB, and returns graph connections. Initially tested top 30, then expanded to all 146 score≥2 investors.
Step 3: Full Batch Results
Ran all 146 medium-to-high confidence investors (score ≥ 2) through graph enrichment. The full batch confirms the pipeline scales — 78% hit rate holds across the entire set, with 27 close matches (similarity score < 0.4) representing high-confidence graph connections.
Top Exact & Near-Exact Matches (score < 0.4)
| LSI Investor | Company | Graph Match | Score |
|---|---|---|---|
| Matt Gilbert | XMS Capital Partners | XMS Capital Partners Exact | 0.285 |
| Owen Willis | Opal Venture Partners | Owl Ventures Fuzzy | 0.304 |
| John Yianni | Earlybird Venture Capital | Earlybird Venture Capital Exact | 0.307 |
| Jeff Terrell | Arboretum Ventures | Arbor Ventures Fuzzy | 0.311 |
| Johan Kampe | Claret Capital Partners | Claret Capital Partners Exact | 0.312 |
| Or Barak | Bank of America Merrill Lynch | Bank of America Merrill Lynch Exact | 0.331 |
| Joey Mason | Claret Capital Partners | Claret Capital Partners Exact | 0.334 |
| Jeff Peters | OrbiMed | OrbiMed Exact | 0.348 |
| Sheila Shah | L.E.K. Consulting | L.E.K. Consulting Exact | 0.356 |
| Ilya Trakhtenberg | L.E.K. Consulting | L.E.K. Consulting Exact | 0.377 |
| Tamir Meiri | Johnson & Johnson | Johnson & Johnson Exact | 0.395 |
Exact = company name matches the graph entity. Fuzzy = close match but different entity (e.g. Arboretum Ventures → Arbor Ventures). 9 of 11 top matches are exact — the graph has strong coverage of these firms.
Pipeline Architecture
Endpoints Created
| Method | Path | ID | Purpose | Status |
|---|---|---|---|---|
GET |
/robert-lab/lsi-scan |
8344 | Scans LSI table, filters by investor titles | Tested |
POST |
/robert-lab/lsi-enrich |
8347 | Takes name+company, returns graph matches | Tested |
Key Takeaways
115 out of 146 score≥2 investors had graph connections. Hit rate held steady from the initial 30-investor test (83%) to the full batch (78%). The knowledge graph has meaningful coverage of the medtech investment ecosystem — not just the SaaS/tech bubble.
27 matches scored below 0.4 (near-exact). 9 of the top 11 are exact company matches: OrbiMed, Earlybird, Claret Capital, Bank of America, J&J, L.E.K. These aren't fuzzy guesses — the graph reveals actual entities with real investment and team connections.
Arboretum Ventures → Arbor Ventures, Opal Venture Partners → Owl Ventures. These are semantically similar but not the same entity. A confidence threshold or exact-match flag would help separate "confirmed in graph" from "similar entity found."
The full batch scan is complete. Next step: expand to the 330 lower-confidence score-1 investors, or deploy the intent-aware query pipeline to production.
What We Learned Building This

The existing production semantic-question function is running on cached results. It does not wrap vector queries in vecf32(), which means once the FalkorDB cache expires, all queries fail with "Invalid arguments". This was discovered during A/B testing — the baseline was returning stale cached results, not live queries. This is a live production bug that needs to be fixed in the existing function, independent of the intent-aware work.
FalkorDB's db.idx.vector.queryNodes requires vecf32([...]) format, not raw arrays. The existing semantic-question function appeared to work without it due to caching. Once cache expired, all queries failed with "Invalid arguments". Fix: wrap all vector queries in vecf32().
The sequence WHERE score < 0.85 ORDER BY score ASC causes a parse error — FalkorDB reads ORD as a broken OR operator. Fix: use the collect() / UNWIND pattern to separate WHERE from ORDER BY with intermediate WITH clauses.
vectors/create-vectors-string returns a JavaScript string from api.lambda, but Xano auto-parses it into a JSON array (1536 floats). The template engine {{$var.embeddings}} renders it as [0.005,-0.024,...]. Must wrap in vecf32() to make FalkorDB accept it.
Almost all nodes (11,948/13,456) share the label Entity. The real typing is in display_label field: Person, Company, VC_Firm, DomainExpertise, SubDomainExpertise, etc. This means label-based Cypher filtering won't work — must use display_label property or edge types.
Groq + Llama 3.3 70B at temperature 0.1 classifies queries in ~200ms with high accuracy. All test queries classified correctly on first try. The confidence scores are useful for fallback logic (low confidence → use general intent).
Timeline
Why This Matters
From the April 14 meeting with Mark: the vision is four agent tools — hiring, fundraising, sales, and web search — each backed by a router agent that picks the right tool based on user intent. This lab is prototyping that router + intent-specific query logic before committing it to production.
The existing semantic-question function was built as a general-purpose Q&A layer. It works well for factual lookups ("What does X do?") but falls flat for action-oriented queries ("Who should I pitch to?") because it doesn't understand intent. The intent-aware pipeline is the first step toward Mark's vision of specialized agent tools.